Prompt sprawl: what the costs look like in production
When prompts live in code, Slack, and spreadsheets, teams pay in deployment overhead, debug time, and silent quality regressions. A look at what the costs are and when they become worth addressing.

TL;DR: When AI teams lack a central place for prompts, costs accumulate quietly: deployment cycles expand, debug sessions stretch, and quality regressions slip through unnoticed. The evidence suggests sprawl is less a technical problem and more an organizational one, with its impact growing in proportion to team size and AI footprint.
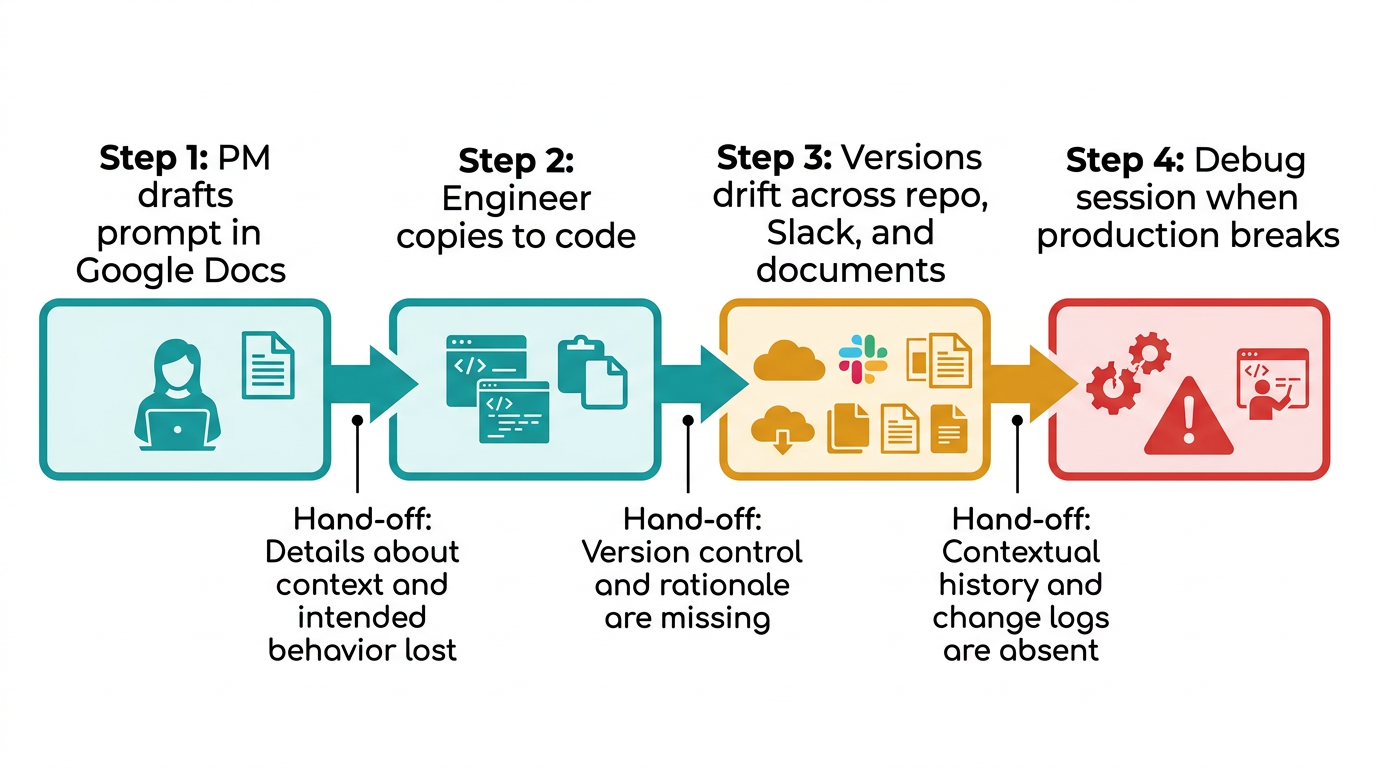
The first version of a prompt usually lives in code. Maybe it is a string constant in a Python file, or a template pasted into a config. It works. Nobody thinks twice about it. Then the team ships more AI features. More prompts appear. A PM drafts one in Google Docs. A data scientist edits another in a notebook. The original engineer is the only person who knows where the production version lives.
This is how prompt sprawl starts, and it rarely announces itself until something breaks.
Where prompts end up and why it matters
Prompt sprawl describes the condition of having AI prompts distributed across code repositories, document editors, chat threads, spreadsheets, and local files, with no canonical source of truth. It is common precisely because it is the path of least resistance. Writing a prompt directly into code requires no infrastructure, no new tools, and no process changes.
What makes it worth examining is that a production prompt is not just a block of text. It typically includes model configuration: temperature settings, which model to call, max token limits, system instructions, and sometimes stop sequences. When these configurations are scattered and undocumented, a change to any one of them is effectively invisible to the rest of the team.
The operational costs of scattered prompts
Research published across multiple LLMOps surveys in 2025 consistently identifies prompt management as one of the top operational pain points for AI engineering teams. The costs break down across several failure modes.
Deployment cycles that compound
When a prompt is embedded in application code, updating it requires a full code deployment. This means coordinating with a release schedule, waiting for pipelines, and bundling a simple wording adjustment alongside unrelated infrastructure changes.
A 2025 analysis of team workflows found that teams managing prompts outside their code repositories iterate significantly faster in practice than those deploying through code. The counterpoint is that decoupling prompts from code introduces its own overhead: teams need deployment environments for prompts, coordination to promote changes from staging to production, and safeguards to ensure prompt changes do not break downstream application behavior. For small teams with few prompts, that overhead often outweighs the benefit.
Version chaos and debug overhead
A pattern documented in Braintrust's 2025 research on prompt versioning: a prompt change degrades quality, the team wants to roll back, but they edited the prompt in place and no longer have the original. The team tries to reconstruct the previous version from memory and often gets it wrong.
When multiple versions of the same prompt live across repositories, documents, and chat threads, engineers report spending significant time simply identifying which version is actually running in production. Some describe multi-hour investigations. Others leave comments in code pointing to external documents, which creates its own drift problem when the documents are updated without corresponding code changes.
Silent quality degradation
One of the more costly failure modes is silent degradation, where a prompt change quietly reduces output quality without triggering any visible error. This happens because most production systems have no baseline measurement for prompt quality. Teams notice it through support ticket increases or user feedback, rather than through automated monitoring.
A 2025 industry analysis on LLM evaluation found that teams without prompt quality metrics may believe an update helped, even when it quietly reduced accuracy or safety. Silent degradation is particularly difficult to detect when the underlying model is updated on the provider's side, changing behavior without any visible prompt change on the team's end.
Cross-functional friction
Building AI features typically involves more than engineers. Product managers prototype prompts in documents. Domain experts review language in spreadsheets. Compliance teams need audit trails. When prompts live in code repositories, most of these contributors are effectively locked out of the iteration process.
A pattern documented across multiple LLMOps platforms: PMs draft prompts in Google Docs, engineers copy them into code, wording drifts during translation, and when issues arise, reconstructing the original intent requires archaeology. The friction is not just inefficiency. Subject-matter expertise that should improve prompt quality reaches the product slowly and imperfectly.
The token cost of unoptimized prompts
Prompt sprawl also creates a token efficiency problem. When prompts are hardcoded and rarely revisited, they tend to accumulate redundant instructions over time. An engineer adds a safety clause. Another adds a formatting instruction. Nobody removes outdated context. The prompt grows.
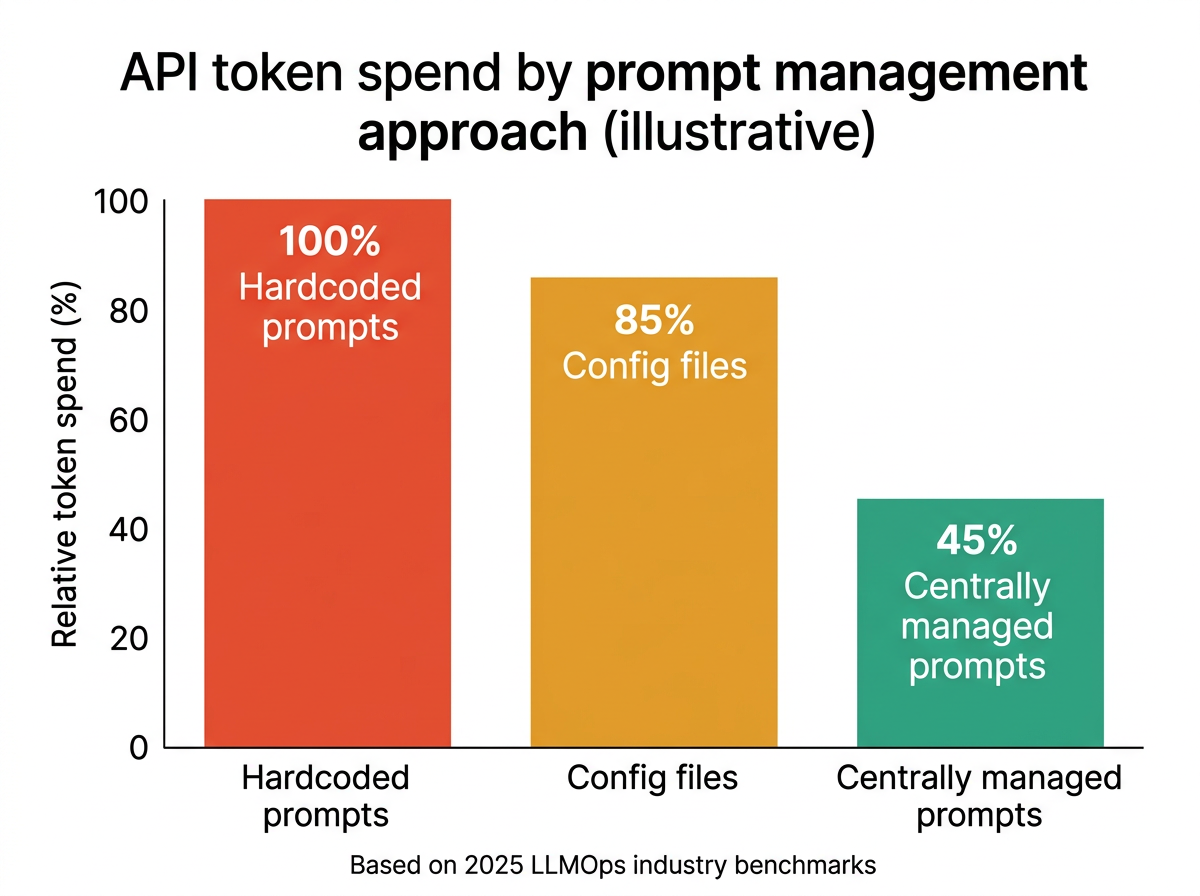
A 2025 LLM cost optimization analysis found that organizations systematically managing prompt content reduce API spend by 30 to 60% compared to teams running unoptimized prompts in production. Token savings typically come from removing redundant instructions, making context conditional rather than always-on, and identifying prompts that have grown far beyond their original scope.
The complication is that trimming a prompt is not obviously safe if you cannot measure what removing a section does to output quality. Teams without evaluation infrastructure tend to err on the side of keeping everything, which compounds the token waste over time.
When informal management still works
For small teams and early-stage products, the overhead of formal prompt management may genuinely exceed the cost of sprawl. A two-person team shipping a single AI feature does not need deployment pipelines or evaluation infrastructure for their prompts. The informal approach scales reasonably until it does not.
The evidence suggests sprawl becomes a material cost primarily when teams cross certain thresholds: multiple engineers touching the same prompts, non-engineers needing to contribute, or enough production traffic that quality regressions have real user impact. A 2025 analysis of PromptOps adoption patterns found that most teams seeking systematic prompt management had already experienced at least one significant production incident attributable to an untracked prompt change.
The question for most teams is not whether to manage prompts more carefully, but when the return on that investment becomes positive. That answer varies by team size, AI footprint, and how frequently prompts change in practice.

What the data suggests
Teams that hit the limits of informal prompt management tend to discover the costs retrospectively, after a production incident or a debug session that runs longer than expected. The data on deployment frequency, debug time, and token spend all point in a consistent direction: the costs of scattered prompts are real but tend to be absorbed invisibly until a team is large enough or moves fast enough for them to surface.
Teams running frequent prompt iterations, large AI footprints, or cross-functional workflows consistently report that the operational overhead of centralization pays back faster than they expected. Teams at early stage or low prompt frequency often find the opposite.
The pattern suggests sprawl is not a universal problem but a predictable one. As AI footprints grow, the probability of hitting the costs documented here increases proportionally.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.