Large context windows and prompt quality: a tradeoff analysis
How context window size affects LLM output quality, cost, and latency. Benchmarks on context rot, four management strategies compared, and context budgeting patterns examined.

TL;DR: Bigger context windows help simple retrieval tasks; they do not reliably help complex reasoning tasks, and they cost significantly more at scale. The teams getting the best results are not using the largest windows - they are being deliberate about what goes in the context and why.
Context windows have grown dramatically: from 4K tokens in GPT-3.5 to 1M+ in Claude Opus 4.6 and Gemini 3 Pro. The marketing pitch is simple: bigger is better, just put everything in the context. But production data tells a more complicated story. This piece examines what the benchmarks, Chroma's 2025 context rot study, and practitioner reports actually show about the relationship between context window size and output quality.
What the benchmarks actually measure
The most widely cited context window benchmark is the Needle in a Haystack test: can a model find a specific fact buried deep in a large context? Modern models perform well here - Gemini 1.5 Pro demonstrated 99.7%+ recall up to 1M tokens. Claude Opus 4.6 scored 76% on long-context retrieval where its predecessor managed 18.5%.
The problem is that single-fact retrieval is the easiest possible long-context task. Chroma's "Context Rot" study (Hong et al., 2025) measured 18 LLMs across multiple task types and found that "models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows." The degradation is much steeper for complex tasks than for simple retrieval.

Simple retrieval tasks maintain high accuracy (85-98%) even at very large context sizes. Complex reasoning tasks - multi-step inference, synthesis across documents, cross-reference analysis - degrade significantly as context grows. Research suggests effective context for complex reasoning is roughly 30-50% of the advertised window. Position sensitivity persists too: models still show 20-25% accuracy variance based on where information sits in the context.
Newer models are meaningfully better. Claude Opus 4.6 demonstrated less than 5% accuracy degradation across its full 200K standard context window. The gap between advertised and effective context is narrowing - but it has not closed, especially for reasoning tasks.
The cost reality
Context window size directly affects cost. Most providers charge per token processed. As of February 2026, using Gemini 3's 2M context for a single request costs roughly $7 in input tokens alone. Anthropic charges a premium beyond 200K tokens: Claude Sonnet 4.6 doubles from $3 to $6 per million tokens, Claude Opus 4.6 goes from $15 to $22.50.
For a high-volume application processing 10,000 requests per day with 50K tokens each, the context strategy choice directly determines whether the economics work. Redis's token optimization analysis found semantic caching alone can cut API costs by up to 73%. Smart context selection (sending only relevant tokens) can achieve 60-80% cost reduction with minimal quality impact.
Four context management strategies
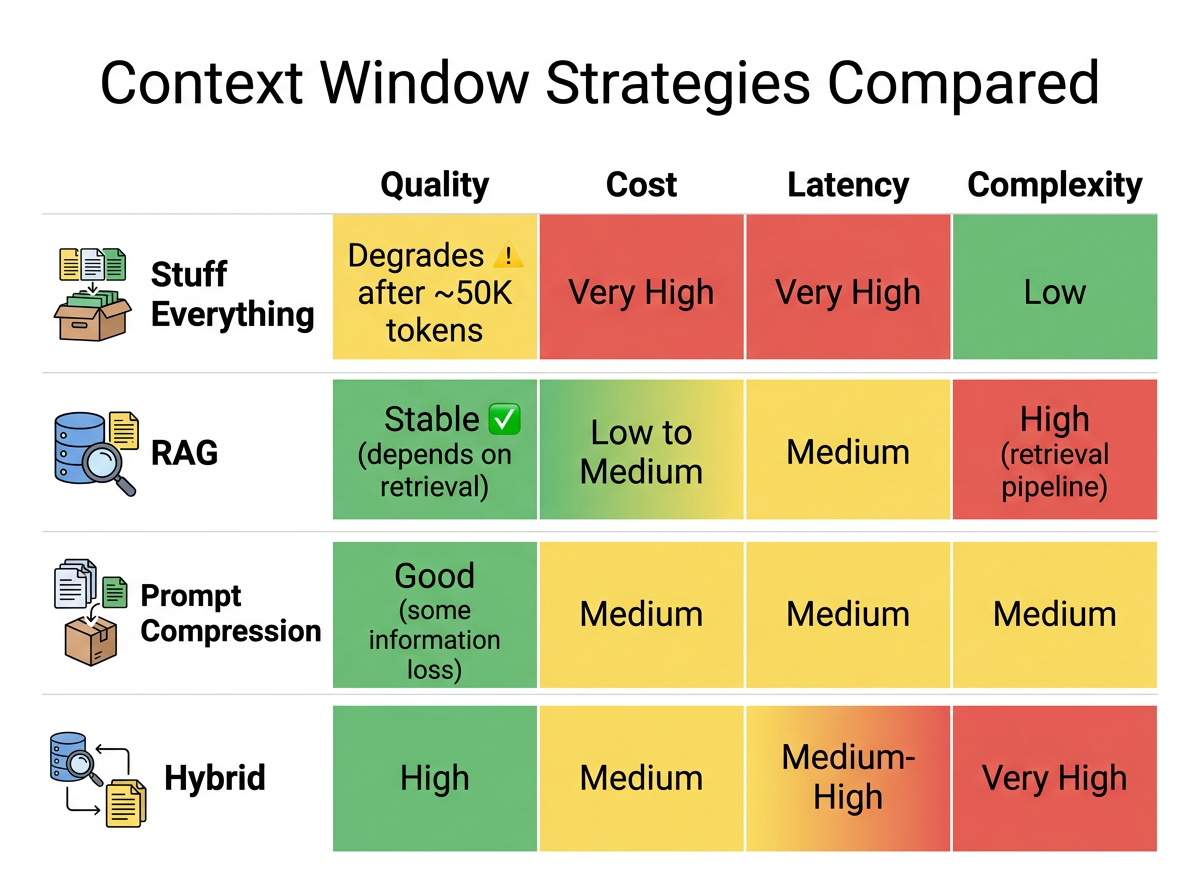
Stuffing everything into the context is the easiest to implement - no retrieval pipeline, no selection logic, the model has access to everything. For requests under ~50K tokens, quality is generally high with modern models. At scale with larger contexts, cost grows linearly and quality for reasoning tasks degrades. A 2025 analysis noted nearly 65% of enterprise AI failures were attributed to context drift or memory loss during multi-step reasoning in large contexts.
RAG retrieves only the most relevant document chunks. Context size stays bounded regardless of how large the document corpus grows. Cost is predictable. Research suggests that sophisticated RAG systems often outperform massive context windows by reducing distracting context that the model has to filter through. The downside: retrieval quality becomes the bottleneck. If the retrieval step misses relevant information, the model cannot compensate - and retrieval errors are harder to debug than context-related quality issues.
Context compression (summarizing or condensing context before sending) reduces token count while preserving key information. Teams report 50-70% token reduction with minimal quality impact on tasks where the compressed context retains what matters. The tradeoff: compression is lossy by definition. Information that seems irrelevant during compression may turn out to be critical for the model's reasoning.
The hybrid approach - RAG for bulk context selection, supplemented by long-context capabilities for specific high-stakes retrievals - gives the best quality-cost profile but is the most complex to implement and maintain. Debugging failures becomes harder because the failure could originate in retrieval, context selection, or the model itself.
When larger windows genuinely help
The data is not uniformly against large context windows. There are specific use cases where bigger windows provide real benefits that retrieval-based approaches struggle to replicate:
Codebase analysis: Understanding code often requires seeing entire files or modules. RAG fragments the dependency graph between functions - missing a key import or interface definition can produce incorrect analysis.
Legal and regulatory review: Documents contain cross-references and conditional clauses that depend on context from other sections. Missing a "notwithstanding Section 4.2(b)" reference can produce incorrect analysis.
Long-running conversations: Multi-turn conversations that span many exchanges benefit from full conversation history. Summarizing past turns risks losing nuance.
For these use cases, the cost and latency overhead may be justified. The key insight is that the decision is not binary - it is about matching context strategy to task type.
What the data suggests
High-volume, cost-sensitive workloads where individual requests do not require deep cross-document reasoning tend to benefit most from RAG or context compression, keeping context under 32-50K tokens. Document analysis, code review, or legal work where comprehensive context matters more than per-request cost may find large context windows worth the premium, especially at lower request volumes. Conversational agents often benefit from a hybrid: RAG for knowledge retrieval combined with full conversation history.
Context window size is one variable among several. A well-curated 32K token context consistently outperforms a carelessly assembled 500K token context on complex reasoning tasks. The teams getting the most consistent results treat context management as an engineering discipline - deliberate about what goes in, why, and at what cost - rather than using maximum available capacity as a default.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.