Multi-agent AI: what it means for prompt management
Gartner tracked a 1,445% surge in multi-agent AI inquiries in a single year. As systems scale from one agent to many, prompt management stops being a single-file problem and becomes a distributed systems challenge.

TL;DR: Gartner reports a 1,445% surge in multi-agent AI system inquiries from Q1 2024 to Q2 2025. As AI products shift from single assistants to coordinated agent networks, prompt management stops being a single-file problem and becomes a distributed systems problem. Research shows 79% of multi-agent failures trace to specification and coordination issues rather than technical bugs.
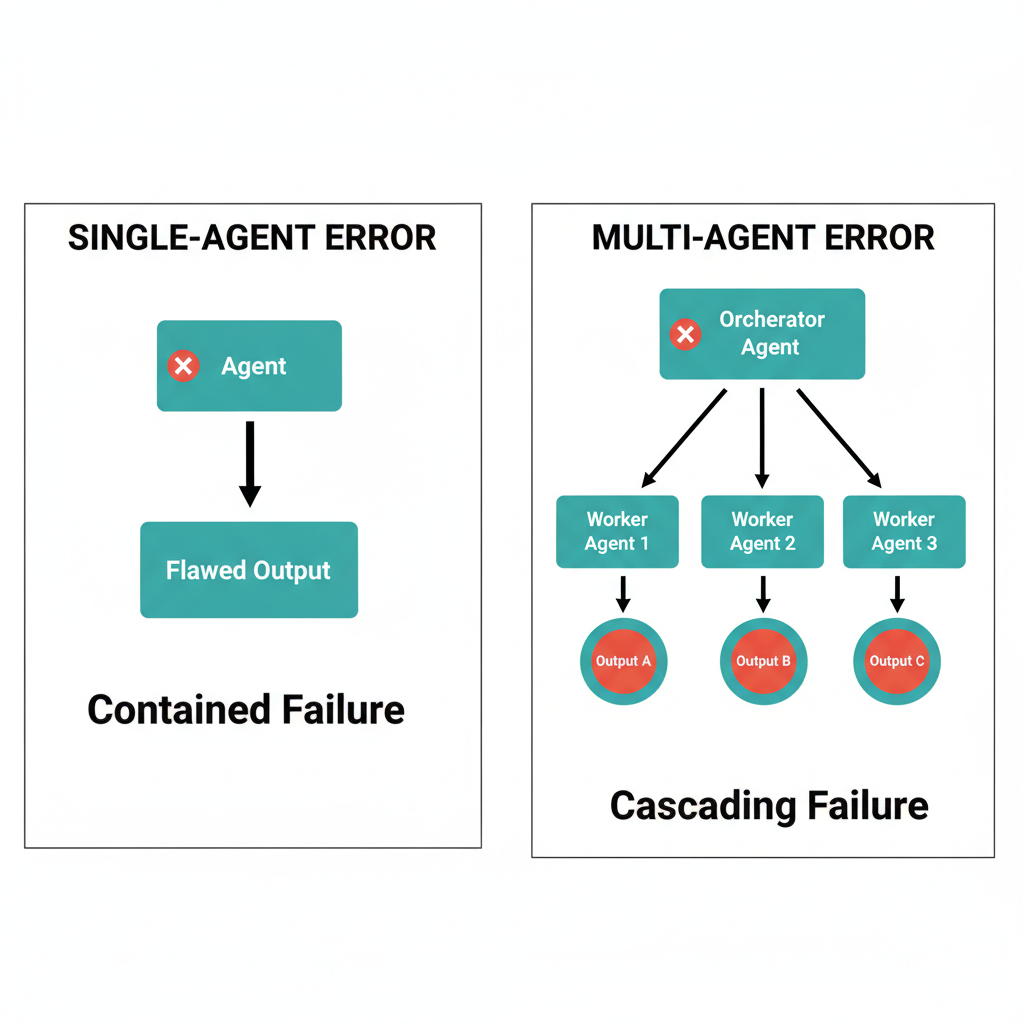
In a single-agent system, prompt management is relatively contained: one system prompt, maybe a few variants, a handful of config parameters. When something goes wrong, the debugging surface is small. When a quality regression appears, the culprit is usually obvious.
Multi-agent systems break all of those assumptions. An orchestrator agent dispatches work to specialized subagents. Each agent has its own system prompt, its own model configuration, its own temperature setting. A wording change in the orchestrator can cascade differently than a wording change in a leaf agent. And a flawed assumption baked into one agent's prompt may silently corrupt the output of every agent downstream.
The scale of the shift
Gartner projected in August 2025 that 40% of enterprise applications would feature task-specific AI agents by the end of 2026, up from less than 5% in 2025. In the same period, Gartner tracked a 1,445% surge in multi-agent system inquiries from Q1 2024 to Q2 2025. These numbers reflect a genuine architectural shift, not just a trend label.
The shift is not simply more agents. It represents a structural change in how AI systems are built: from single large prompts handling many cases to specialized agents, each with a focused role, collaborating under an orchestrator. That structure changes the prompt management problem in ways that are not always obvious when building the first prototype.
Why multi-agent systems change the prompt problem
One flawed prompt, many downstream failures
A January 2026 analysis of multi-agent failure patterns identified what the author called the bag of agents anti-pattern: when agents operate without proper coordination topology, individual errors do not stay contained. The analysis documented a 17x error multiplication effect in unstructured multi-agent systems, where a mistake by one agent is amplified rather than caught as it moves downstream.
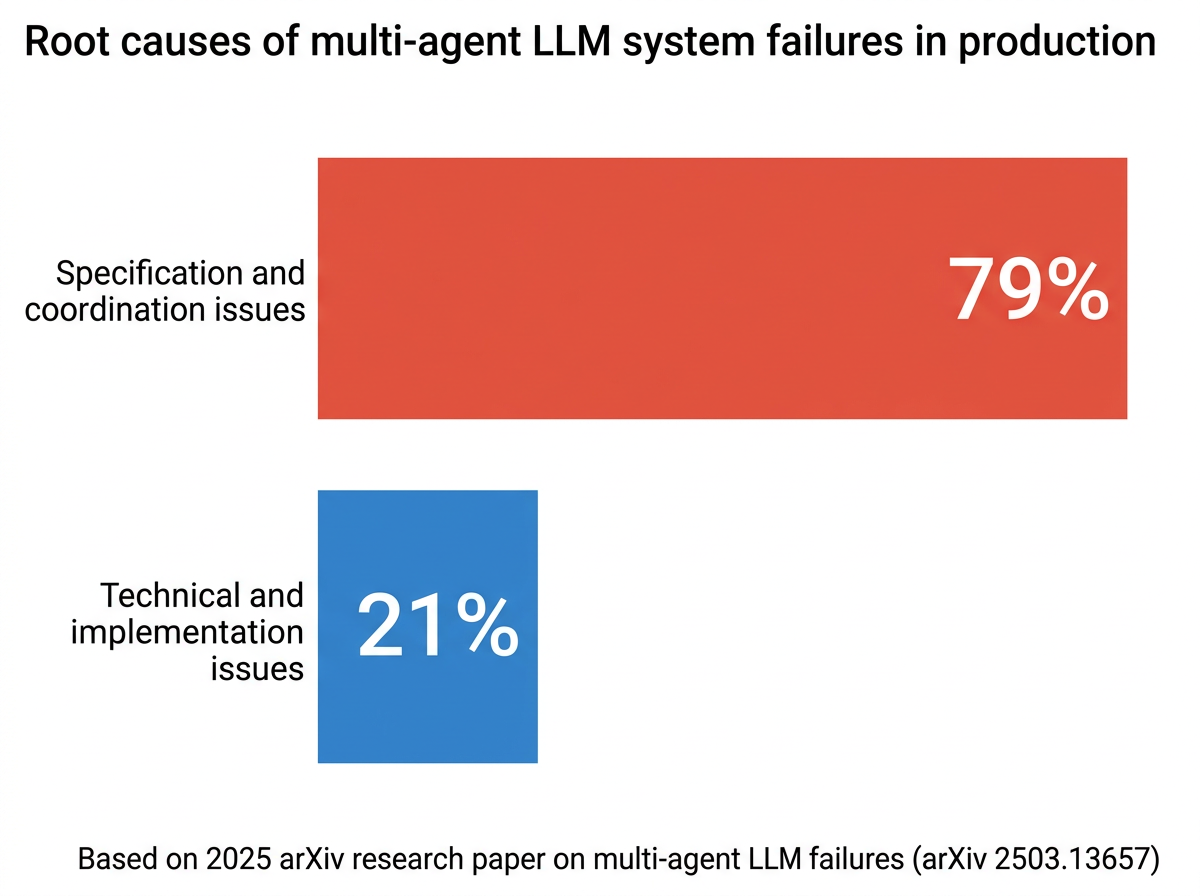
The root cause in most cases is not a code bug. A 2025 research paper on multi-agent LLM failure analyzing production deployments found that 41 to 86.7% of multi-agent systems fail in production, with approximately 79% of those failures tracing back to specification and coordination issues rather than technical implementation. The implication is direct: the quality and consistency of the prompts defining each agent's role and behavior is the primary reliability variable in most multi-agent deployments.
Per-agent versioning vs. shared prompt libraries
Single-agent systems typically version one prompt or a small set. Multi-agent systems have to answer a harder question: should each agent maintain its own independent prompt version, or should shared behaviors live in a common library that all agents reference?
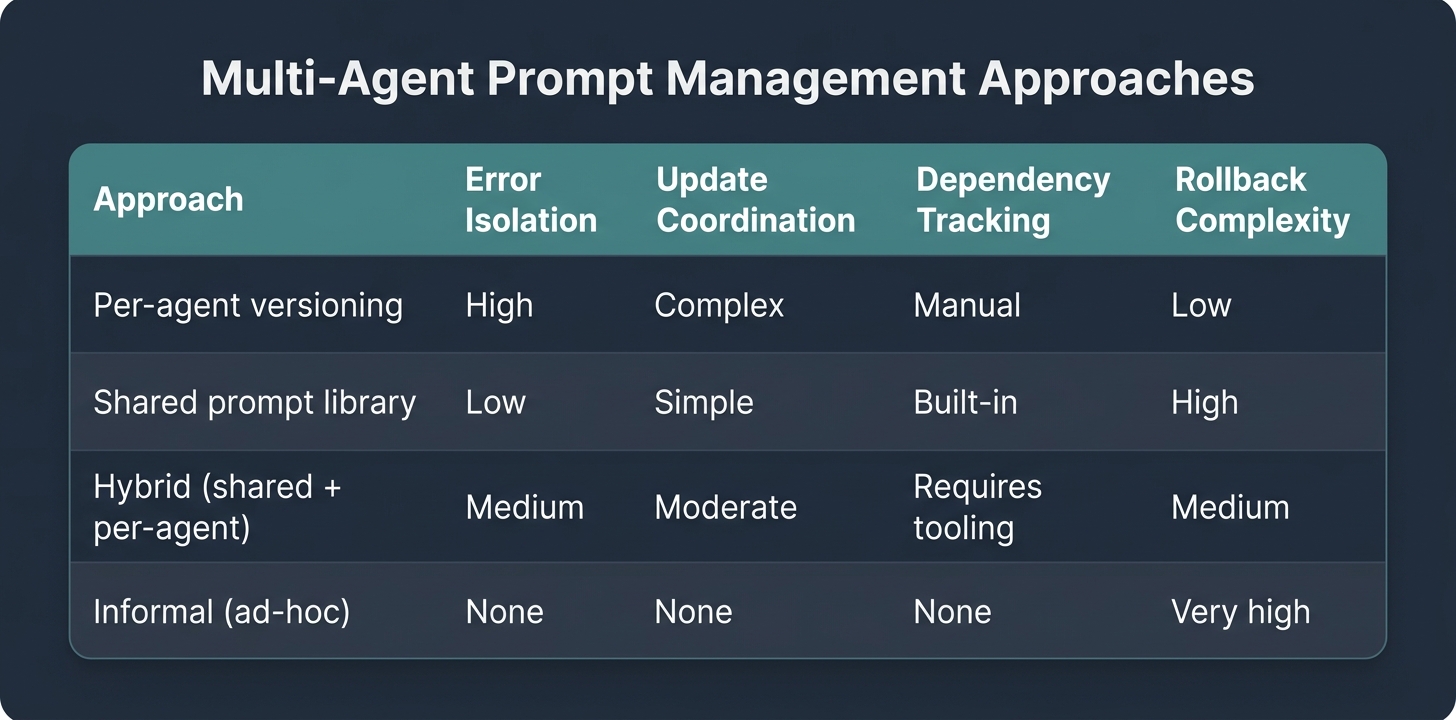
Per-agent versioning preserves isolation. A change to the summarizer agent's prompt does not touch the analyst agent. Teams can update, test, and roll back each agent independently. The tradeoff is coordination overhead: when a shared policy changes, the same update has to be applied across every agent, with the risk that some get updated and some do not.
Shared prompt libraries reduce that drift risk. A common instruction set or knowledge base can be maintained once and pulled by all agents. The tradeoff is coupling: a bug in the shared component propagates to every agent that references it simultaneously.
Most teams with production multi-agent systems report using a hybrid: shared libraries for cross-cutting concerns such as safety rules, output format guidelines, and brand voice, and per-agent versioning for role-specific behavior. That hybrid arrangement creates its own management question: how do you track dependencies between shared components and the agents that use them?
Orchestrator prompts and coordination
In hierarchical multi-agent architectures, the orchestrator prompt carries disproportionate weight. It defines what tasks get delegated, to which agents, in what sequence. An under-specified orchestrator prompt is the most common single point of failure in multi-agent pipelines. As the research found, if the initial goal or system prompt is under-specified or open to interpretation, agents will diverge in behavior.
This divergence is distinct from a single-agent regression. In a single-agent system, a vague prompt produces vague output. In a multi-agent system, a vague orchestrator prompt can produce divergent output from different agents on the same task, silent conflicts between agents' conclusions, or loops where agents repeatedly hand off unresolved work.
What the failure data shows
The 2025 Gartner analysis of agentic AI projects found that more than 40% of agentic AI projects are expected to be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. The inadequate risk controls category overlaps substantially with prompt governance: in multi-agent systems, there is often no systematic record of which version of which agent's prompt is running in production, who approved the last change, or how a given output can be traced back to the prompts that produced it.
One financial services firm, cited in multi-agent orchestration research, lost an estimated $2 million due to poor state management in a multi-agent deployment, where duplicate processing went undetected because agents lacked a consistent view of shared context. While that failure involved state management broadly, the underlying cause was a coordination gap that prompt-level specifications are supposed to prevent.
The tradeoffs in managing prompts at scale
It is worth acknowledging the counterargument directly. As frontier models improve, some practitioners argue that prompt quality matters less, because more capable models recover better from ambiguous instructions. There is data to support this directionally: current-generation models handle under-specified prompts more gracefully than their predecessors. The argument is that investing heavily in prompt management infrastructure is optimizing for a problem that models will increasingly solve themselves.
The counter-data is the failure rate. If frontier models were handling orchestration ambiguity reliably, production failure rates would be declining. The research suggests they are not, at least not at the pace needed for enterprise deployment. The 79% specification-failure figure comes from production systems using current-generation models, not from systems running on older infrastructure.
The more defensible position, based on available evidence, is that better models shift the threshold at which prompt quality becomes critical, but they do not eliminate the requirement.
What the data suggests
Teams shipping multi-agent systems for the first time often discover the prompt management complexity after the fact, during the first significant production failure. The data on failure rates and failure attribution is consistent: specification quality drives most of the reliability variance.
Teams that treat each agent's prompt as a distinct, versioned, testable artifact tend to have better observability into which part of their pipeline is producing which output. Teams that manage all agent prompts informally tend to find root-cause analysis significantly harder when things go wrong.
The architecture of a multi-agent system does not automatically require more sophisticated prompt tooling. A two-agent pipeline with stable, well-defined agent roles may be manageable with simple approaches. But as agent count grows, as orchestration becomes dynamic, and as teams update agent behaviors independently, the prompt management surface expands proportionally.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.