Prompt engineering techniques most developers skip
Nine prompt engineering techniques backed by research that most developers skip. Emotional prompting, position bias, context engineering, and the tricks that actually move the needle in production.

TL;DR: Most prompt engineering advice rehashes the same few patterns: be specific, give examples, use chain-of-thought. But research from 2025 and 2026 has surfaced techniques that are both counterintuitive and measurably effective. Emotional prompting improves LLM performance by up to 115% on certain benchmarks. Instruction placement can swing output quality by 30%. Telling a model what not to do often backfires. And the shift from prompt engineering to context engineering changes how production systems should be architected. Here are nine techniques, all research-backed, that most developers have never tried.
Every developer working with LLMs has read the same advice. Be specific. Give examples. Use chain-of-thought reasoning. These are table stakes now, and they have been for two years.
The techniques that actually separate production-quality prompts from mediocre ones are less intuitive. Some sound like superstition. Some contradict common sense. All of them have research behind them, and most developers skip them entirely.
The techniques that sound too simple
The most overlooked prompt engineering techniques are not complex. They are embarrassingly simple, which is exactly why experienced practitioners miss them.
Separating instructions from context with explicit delimiters (XML tags, Markdown headers, or labeled sections) consistently outperforms freeform prose in every controlled study. Anthropic's own prompt engineering documentation recommends XML tags for Claude. OpenAI's best practices recommend Markdown headers for GPT models. Google's Vertex AI documentation recommends structured sections for Gemini.
The reason is mechanical, not aesthetic. Transformer attention mechanisms process structured text differently than unstructured prose. When a model encounters <instructions> tags, it allocates attention to that block more reliably than when instructions are mixed into a wall of text. Research on context dilution confirms this: long unstructured prompts dilute the influence of critical instructions.
The second embarrassingly simple technique: putting your actual question or instruction at the end of the prompt, after all the context. Studies show this improves response quality by up to 30% on complex, multi-document inputs. Models exhibit both primacy bias (favoring early tokens) and recency bias (favoring late tokens), and in practice the recency effect is stronger for instructions. Your context goes first. Your question goes last.
Position bias and instruction order
Position bias deserves its own section because the effect size is larger than most developers expect.
LLMs do not process all parts of a prompt equally. Research on positional bias in transformer models shows that information placed at the beginning and end of the context window receives disproportionate attention. The middle gets compressed.
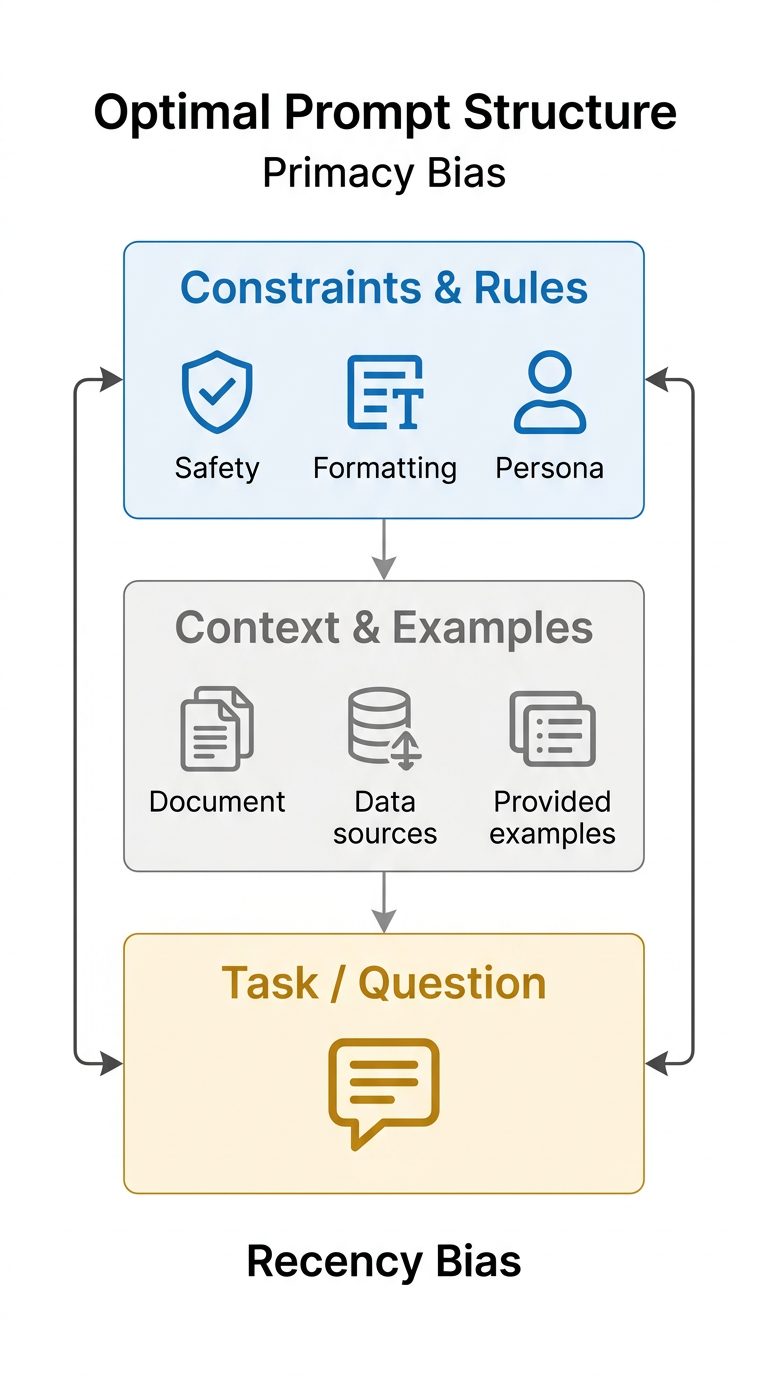
For production prompts, this means three things.
Critical constraints (safety rules, format requirements, persona definitions) belong at the very beginning of the system prompt. They benefit from primacy bias and set the frame for everything that follows.
The user's actual request or the core task description belongs at the very end. It benefits from recency bias and becomes the immediate trigger for generation.
Supporting context, examples, and background information go in the middle. This is the lowest-attention zone, but retrieval-augmented context is less sensitive to position because models are trained to extract relevant information from document-like content regardless of placement.
Teams that restructure their prompts to follow this pattern (constraints first, context middle, task last) typically see measurable improvements in instruction adherence without changing a single word of the actual instructions.
Emotional prompting (yes, really)
This is the technique that sounds the most like superstition. It is also one of the most well-studied.
EmotionPrompt, published in 2023 and replicated across multiple studies through 2025, demonstrated that appending emotional stimulus phrases to prompts improves LLM performance. The effect is not small. Researchers found an 8% relative improvement in instruction induction tasks and a 115% improvement on BIG-Bench reasoning benchmarks.
The emotional stimuli are not complex. Phrases like "This is very important to my career" or "You'd better be sure" or "Take a deep breath and work through this step by step" consistently improve output quality across GPT-4, Claude, and Llama models.
A related study explored both positive and negative emotional stimuli. Positive stimuli (encouragement, expressions of confidence in the model) improved accuracy. Negative stimuli (expressions of doubt, anger, or insecurity) showed mixed results: they sometimes motivated more careful responses but also increased the risk of the model producing defensive or hedging language.
The working theory is that LLMs absorbed patterns from their training data where emotionally charged requests correlated with higher-stakes contexts, which in turn correlated with more careful, detailed human responses. The model learned to produce more careful output when the emotional tenor of the input suggests the stakes are high.
For production use, the practical takeaway is narrow but real. Adding a single line of emotional context ("Accuracy is critical for this task" or "This output will be reviewed by domain experts") costs almost nothing in tokens and reliably improves instruction following. It is not a replacement for clear instructions. It is a multiplier on top of them.
The context engineering shift
Anthropic published an engineering guide on context engineering that reframes how production systems should think about prompts. The core argument: prompt engineering optimizes the instruction. Context engineering optimizes everything the model sees.
The distinction matters because most production failures are not instruction failures. They are context failures. The model had the wrong information, too much information, or information in the wrong order.
Context rot is the term Anthropic uses for the degradation in accuracy as token count increases. It stems from the transformer architecture's O(n-squared) complexity in attention relationships. More tokens means more attention relationships, which means each individual token gets proportionally less attention.
The practical response is progressive disclosure: instead of pre-loading all possible context into the prompt, maintain lightweight references (file paths, IDs, query parameters) and load relevant data just in time. This is the architecture behind Claude Code and similar agent systems. The model starts with minimal context and incrementally discovers what it needs through tool use.
For non-agent applications, the same principle applies at a smaller scale. A customer support prompt that loads the entire customer history into context performs worse than one that loads only the relevant recent interactions. A code review prompt that includes the entire file performs worse than one that includes only the changed functions with minimal surrounding context.
The counterintuitive finding: even as context windows grow to millions of tokens, context engineering becomes more important, not less. Models are trained primarily on shorter sequences and develop less reliable behavior at the long end of their context window. A 200K-token context window is not an invitation to use 200K tokens. It is a ceiling, not a target.
Negative instructions do not work
"Do not hallucinate." "Do not make up information." "Do not include any markdown formatting."
Developers write negative instructions constantly. Research consistently shows they are less effective than positive equivalents.
The mechanism is analogous to how humans process negation. "Do not think of a pink elephant" activates the concept of a pink elephant. Similarly, "Do not include disclaimers" requires the model to activate the concept of disclaimers and then suppress it. The activation often bleeds through into the output.
The OpenAI prompt engineering guide explicitly recommends telling models what to do instead of what not to do. "Respond only with verified facts from the provided context" outperforms "Do not hallucinate." "Use plain text without any formatting" outperforms "Do not use markdown."
This extends to behavioral constraints. "Respond in three sentences or fewer" works better than "Do not write long responses." "If you are unsure, say 'I don't have enough information to answer that'" works better than "Do not guess."
The pattern is consistent across models and task types. Positive framing gives the model a clear target. Negative framing gives it a thing to avoid while leaving the actual target ambiguous.
Co-design: let the model write its own prompt
One of the most underused techniques in production systems is asking the model to refine its own prompt. The co-design pattern works in two steps: describe what you need the prompt to accomplish, then ask the model to generate the optimal prompt for that task.
The results are often better than hand-crafted prompts because the model can optimize for its own processing patterns. A prompt that is clear to a human developer is not always clear to the model, and vice versa. The model knows (in a statistical sense) which phrasings it responds to most reliably.
Research on prompt optimization confirms this. Gradient-based approaches like ProTeGi use text-based gradients to iteratively refine prompts, and even simple ask-the-model approaches outperform manual iteration in many cases. A 2024 survey identified over 50 distinct text-based prompting techniques, and the most effective ones often look nothing like what a human would write.
The production version of this technique is not asking the model once and shipping the result. It is systematic: generate multiple prompt candidates, run them through an eval suite, and select the one that performs best on your specific metrics. Tools like EchoStash evals support 14+ assertion types (JSON schema validation, cosine similarity, LLM-as-judge, and more) that let you compare prompt variants against test datasets automatically.
Token optimization through structure
The economics of prompt engineering are straightforward: every token costs money, and most production prompts waste tokens.
An analysis comparing two real production systems found a 76% cost difference between a verbose prompt style and a structured prompt style at the same daily volume. The verbose approach cost $3,000 per day at 100K calls. The structured approach cost $706 per day. Same task, same model, different prompt architecture.
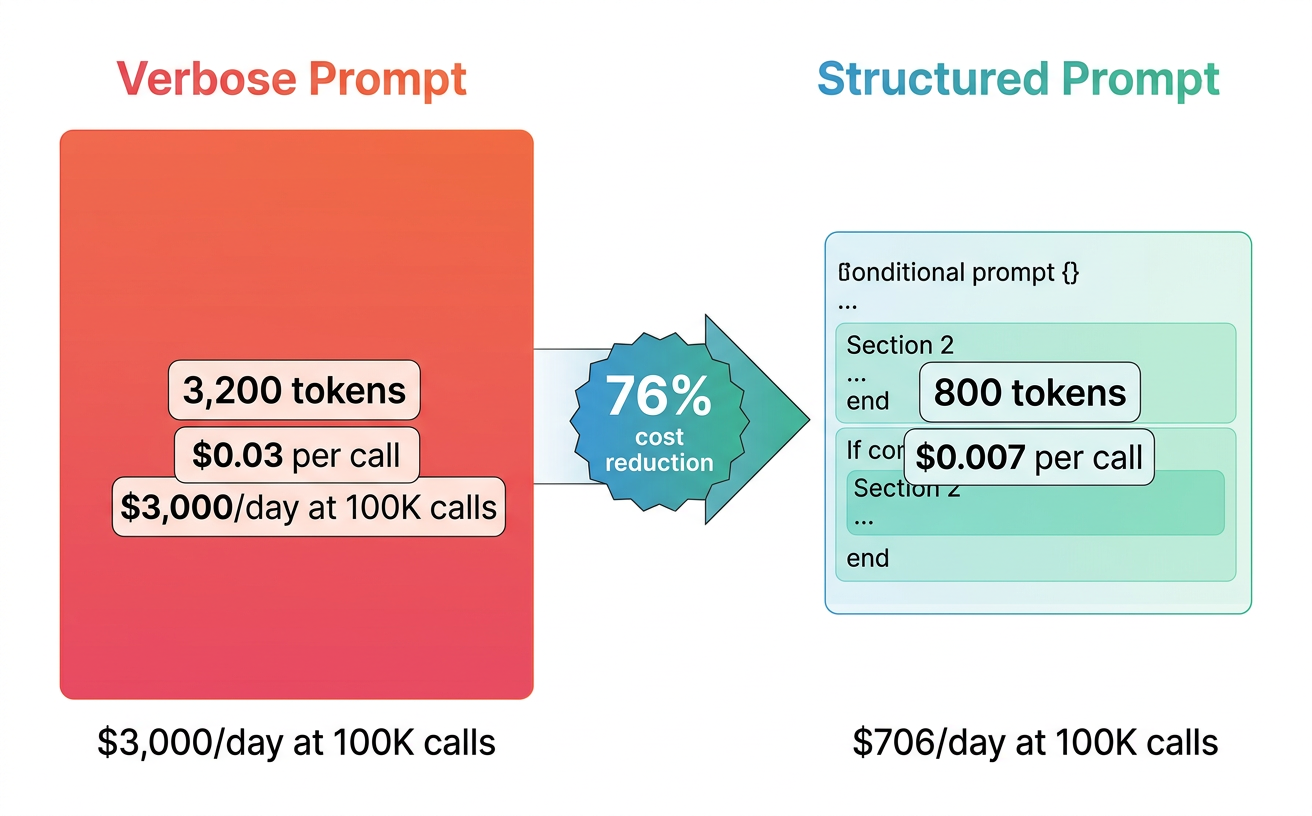
The most effective token optimization techniques are structural, not cosmetic. Removing articles ("the", "a") from instructions saves a few tokens. Restructuring the prompt to conditionally include only relevant context can save 50-75% of tokens.
Dynamic prompt templates address this directly. Instead of sending the entire prompt every time, including all rules for all user tiers, all edge cases, and all scenario-specific instructions, a dynamic template evaluates conditions at render time and includes only what is relevant for the current request. EchoStash's PDK implements this with conditionals, variables, and reusable sections that render in under 50ms.
The counterintuitive finding from the research: optimizing for quality first, then optimizing for cost, produces better results than trying to optimize both simultaneously. Teams that start by making their prompts as effective as possible and then systematically reducing token usage without quality degradation outperform teams that start with cost constraints.
What the research suggests
The gap between prompt engineering advice online and prompt engineering research in production is wide. Most articles still focus on basic techniques that were sufficient in 2023. The techniques that matter for production systems in 2026 are more nuanced: structural optimization, position-aware instruction design, emotional context as a performance multiplier, and the broader shift from prompt engineering to context engineering.
Nine techniques is not an exhaustive list. But these nine share a common trait: they are all backed by published research, they all produce measurable improvements, and they are all underused in production systems today.
The teams that treat prompt engineering as a craft rather than an afterthought consistently outperform on quality, cost, and reliability. The techniques are available. The research is public. The question is whether the prompts are being managed with the same rigor as the rest of the codebase.
Related links
Stay in the loop
Get notified when we publish new posts. No spam, unsubscribe anytime.